

Capish Reflect
With Usability in Mind.
Capish Reflect is intuitive and easy to use. Since the application runs in a normal web browser, it’s the perfect tool and companion for team work regardless of where you are.
Capish Reflect is a powerful, purpose-built software for clinical science, designed to transform how you explore and interact with complex data. Its advanced graph database and standardized ontology enable seamless access, visualization, and analysis, unlocking new insights with ease.
No more chasing scattered datasets or writing code. With everything in one structured, future-ready space, answers are instant, workflows are smooth, and decisions are smarter.
EXPECT THIS FROM CAPISH REFLECT
- All data accessible through a normal web browser.
- Meets the highest security standards.
- Easy to use with point and click interface.
- No coding skills required, not even for the most complex data queries and explorations.
- Customizable per user role.
- Interoperable data formats.
FUNCTIONS AND FEATURES
- Search, filter and access data and specific subsets effortlessly.
- Easy save and share – perfect for collaborations.
- Quickly find and identify outliers.
- Create cohorts and find similar patients.
- Generate clear, insightful, and visually, compelling representations in no time.
- Customize views to focus on the data that matters most.
STREAMLINE YOUR WORK
- Instantly access and interact with data using an intuitive, query-driven interface that adapts to your specific needs.
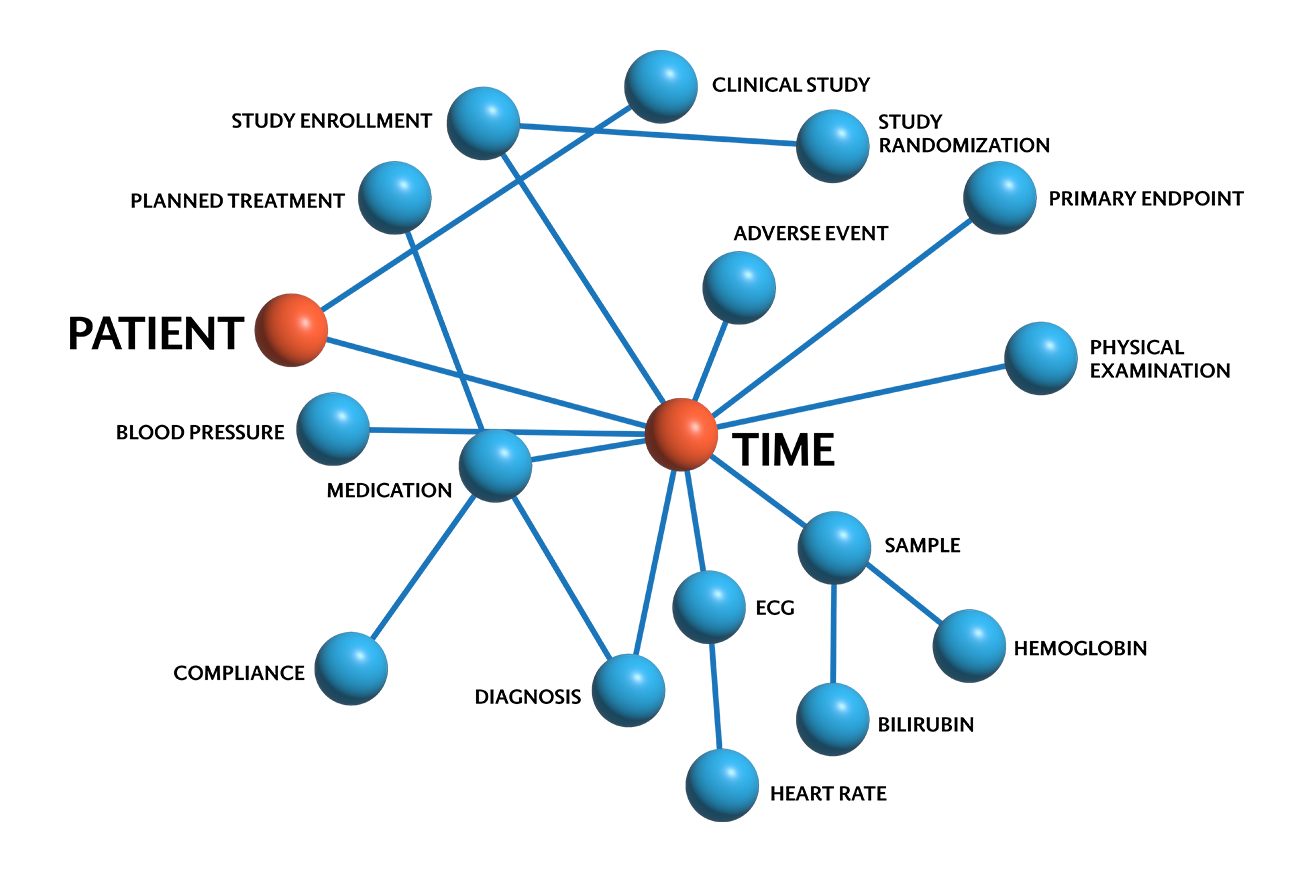
- Simplify complex workflows by visualizing connections across diverse datasets, enabling faster decision-making and more efficient collaboration.
FASTER AND BETTER ANSWERS
- Quickly uncover key insights from complex datasets, reducing time spent searching and analyzing information.
- Enhance accuracy with intelligent data connections that lead to more precise and actionable responses.
LIKE A PARTNERSHIP
- Your journey to graph data is made as smooth as possible by Capish’s data managers.
- Close collaboration during the entire project.
- Training and recurrent training (if needed) of your staff and organization.
- Ongoing support, ensuring seamless integration and success.

With its powerful data exploration capabilities, you can quickly uncover insights and make informed decisions with Capish Reflect. Think of it as a partnership, where Capish works alongside you to simplify complex tasks, boost productivity, and help you achieve results with greater efficiency and precision.

Developed with the user in mind, Capish Reflect is intuitive and easy to use. Since the application is web based, it’s the perfect tool and companion for team work regardless of where you are.
The modular functionality in Capish Reflect allows endless flexibility in designing your applications. However, you don’t have to start from scratch. Instead, you can choose a proven application template including the features you and your clients need.
Look how easy you can spot and explore unusual data points with Capish Reflect.

Structure
Data curation is the process of organizing and structuring data for easy access and use, and transforming it into a strategic asset. With Capish, your data is streamlined, optimized, and future proofed.

Innovate
Capish Reflect is a powerful data exploration tool that enables you to query and analyze complex datasets. It allows you to explore your data on a whim, uncovering opportunities and insights.

Collaborate
Attract external partners, scientists, and investors by offering a unique platform. Capish Solutions is your trusted collaboration platform, designed to streamline interactions across teams and stakeholders.
Supercharge Your Analysis.
Capish Reflect is a solution that transforms complex data into actionable insights in real-time. With this tool, you're not just working with data; you're uncovering hidden patterns, visualizing connections, and streamlining your process with ease.
Forget outdated methods and slow tools. Capish Reflect empowers you to unlock your data's full potential, combining intuitive interfaces with cutting-edge technology. It's more than a product – it's like having a partner guiding you every step of the way, turning raw data into a powerful assets.
Want to know more?
Book an online demo, or get in contact with us for a physical meeting, and one of our representatives will show you how Capish can streamline your research.

- Introduction to Capish Reflect.
- Introduction to the Curation Services.
- US or European time zones.
- Examples of studies and real life examples.
- Use case scenarios. How we can streamline your organization.
- 30 minutes to an hour – you decide!