

The Frequently Asked Questions.
⇒ Is your question not covered? Contact us and we'll help you!

Who we are
Capish specializes in providing innovative solutions for organizing, visualizing and exploring complex data, with a focus on the life sciences sector.
What does Capish do?
Capish specializes in providing innovative solutions for the life science sector. Capish’s tools empower organizations to gain meaningful insights, streamline clinical trials, and improve research outcomes by making data more accessible and actionable by utilizing state-of-the-art graph data technologies.
What makes Capish unique?
Capish’s uniqueness lies in an innovative approach, that allows users to ask questions and extract insights from datasets in a simple, flexible, and highly efficient manner.
Capish have a unique combination of innovative software development and clinical data management experts
Does Capish offer software or services?
Capish offers both software and expert services, providing comprehensive solutions for scientific data exploration and visualization.
At its core, Capish combines innovative software with tailored services like data modeling, harmonization, and custom application design.
These tools simplify the analysis of complex datasets, empowering users to intuitively access, explore, and interact with their data.
With a focus on efficient data processing and seamless integration, Capish’s solutions make data more accessible, understandable, and actionable for life sciences and clinical research.
Is Capish only focusing on Life Sciences?
Capish primarily serves the life sciences and healthcare industries, including pharmaceutical companies, biotech firms, clinical research organizations (CROs), and regulatory bodies.
However, its solutions are also suitable for other sectors that require complex data analysis and visualization.
Where is Capish located?
Capish is headquartered in Sweden, with a growing presence in the United States and other markets where life sciences and clinical research are prominent.

Implementation
Capish offers a smooth transition to graph data. Our skilled curation and data management team, converts your clinical data to future proof XML-formats, to be seamlessly adopted to Capish Reflect for your data exploration and discovery.
How is a solution implemented?
The implementation process is designed to be smooth and efficient. It is conducted in close collaboration with the customer to ensure that the project’s specific requirements are fulfilled.
Implementation typically begins with a detailed assessment of the customer’s needs, followed by curation and configuration of the solution. All parts of the solution are thoroughly tested before taken into production.
Once testing is complete, Capish provides training and support to ensure the customer is fully equipped to use the system effectively.
How long does the implementation process take?
The timeline largely depends on the purpose of the solution and the project’s specific requirements. It also depends on the complexity and volume of the data. However, with Capish’s proven project models and adherence to best practices, Capish ensures a swift setup of user workspaces, minimizing delays and getting you up and running quickly.
How will the data be stored, at the customer's premises or with Capish?
Capish provide flexible storage options to suit the customers’ needs. One solution is cloud-based storage using Microsoft Azure, offering secure and reliable access to your data. Alternatively, customers can choose to store their data on their own on-premises servers for more control.

Products
Capish’s products are designed to empower users to explore their data quickly and intuitively, uncovering correlations that may be difficult to identify with traditional systems. The complete solution encompasses data curation and is built with Capish Reflect, offering a seamless, integrated experience.
What kind of a applications do Capish offer?
Capish offers three types of products:
- Capish Reflect, a data exploration and visualization software.
- Capish Curation is a service where data is harmonized, standardized and quality controlled.
- Capish Pronto, customized and ready to go applications for use with Capish Reflect.
These products together help organizations navigate and explore complex datasets. The solution is designed to support for example clinical trials, research and development, and data-driven decision-making in the life sciences.
What are the unique values in a solution from Capish?
The solutions from Capish offers unique advantages, including the ability to work with graph data, enabling seamless exploration and visualization without the need for complex coding or scripts.
The deep industry knowledge and experience in clinical data empowers Capish to deliver tailored project models and specialized tools for harmonizing and integrating diverse clinical data sources.
This combination of ease of use and expertise makes Capish a powerful, efficient solution for organizations seeking to unlock insights from their data.
Does Capish offer any standardized, ready-to-use applications?
Yes, Capish offers a standardized solution that serves as a foundation for creating customized applications tailored to customer specifications. This approach allows us to provide ready-to-use capabilities while ensuring the flexibility to adapt the solution to meet the unique needs of each organization.
Are solutions from Capish secure and compliant?
Yes, Capish solutions are built with the highest standards of security and compliance in mind.
Capish offer flexibility in choosing your preferred cloud provider, adhere to best practices, and ensure full compliance with GDPR regulations. Patient safety is always our top priority, and the solutions include robust features like audit trails to maintain transparency and accountability.
Capish is committed to delivering secure, compliant solutions that meet the stringent requirements of the industry.
Can Capish integrate with a customer’s existing data sources?
Yes, Capish offers seamless integration with customers’ existing data sources. The platform supports a wide range of connectors and APIs that enable smooth data exchange between Capish and other systems.
Whether the data resides in clinical databases, spreadsheets, or cloud storage, Capish can harmonize and integrate this information efficiently. This flexibility ensures that customers can leverage their existing infrastructure while benefiting from the powerful capabilities Capish provides for data exploration, visualization, and interpretation.
How future proof is a Capish solution?
Capish solutions are designed with long-term adaptability in mind, ensuring that the platform remains relevant and capable of meeting emerging challenges.
The solutions are also fully compliant with current and upcoming regulations, such as GDPR and other data privacy laws, to ensure ongoing legal adherence.
In terms of interoperability, Capish follows industry standards that allow seamless integration with a wide range of systems and data sources. This ensures that your solution can connect with new tools and platforms as they emerge, providing the flexibility to adapt to future technological advancements without requiring significant changes to your existing infrastructure.

Capish Reflect
Capish Reflect, a web based software, offers unique advantages, including the ability to work with graph data, enabling seamless exploration and visualization without the need for complex coding or scripts.
What are the key features of Capish Reflect?
Focus is on enabling users to quickly navigate and analyze complex datasets, providing them with the tools to extract meaningful insights and make informed decisions.
Capish Reflect is specialized in robust search and filtering features that allow users to create tailored cohorts. These cohorts can be saved for future use and easily compared within the application, facilitating efficient data analysis.
Is Capish Reflect easy to use?
Yes, Capish Reflect is designed with usability in mind. It requires no coding, making it accessible to users with varying levels of technical expertise. That’s why we say “With Capish you can”.
While the interface is intuitive for general use, a bit of training may be beneficial for users looking to explore data in greater depth.
This ensures that both new and advanced users can quickly harness the power of Capish Reflect to gain valuable insights from their data.
How does Capish Reflect support collaboration?
Capish Reflect allows multiple users to work on the same dataset, share insights, and build queries together. It provides a versatile user interface for easy navigation, making collaboration more efficient by enabling teams to explore data collectively.
Is Capish Reflect compliant with industry standards?
Capish Reflect adheres to industry standards, including those for clinical data management and regulatory requirements. It is built to support compliance by ensuring data integrity, traceability, and seamless data management throughout the clinical trial lifecycle and beyond.
This robust adherence helps organizations maintain regulatory compliance while managing data efficiently across the entire data lifecycle.
What kind of data can Capish Reflect handle, and can it handle large datasets?
Capish Reflect can handle a wide variety of data types, including structured and unstructured data. It is designed to integrate clinical trial data, safety data, laboratory results, patient demographics, and other research-related information for comprehensive analysis.
Capish Reflect is built to manage large and complex datasets, making it suitable for handling comprehensive clinical trial data or extensive research datasets.
What kind of insights can Capish Reflect provide?
Capish Reflect enables users to identify patterns, correlations, and trends in their data. By exploring relationships between different data points, users can gain insights that may support decision-making in clinical research, such as understanding adverse event triggers, patient subgroup responses, or treatment outcomes.
The more variables and the more complex data is, the more value the solution can give.
Capish Curation
Data curation involves ensuring that data is consistent, standardized, and properly described, making it suitable for integration with other datasets. The goal is to transform the data into a format that ensures easy accessibility and usability in subsequent stages of analysis or application.
What is the benefit of having curated data?
Data curation provides a foundational step that can be completed once and then built upon, offering long-term time savings. The curated and quality-controlled data is available in XML format, which ensures both reliability and futureproofing, making it adaptable for ongoing use and integration with other systems.
What are the steps in data curation?
Capish begins the data curation process by performing an inventory to assess the necessary steps for aligning the data with the ontology. The data is then harmonized and structured according to the information model that is created.
Following harmonization, the variables are mapped to the appropriate Fields within the ontology.
Finally, a quality check based on predefined rules is conducted, and if the data meets all criteria, XML files are generated for further use.
What are the effects of data curation?
The key effects of data curation include ensuring that variable values are consistent, defining variables clearly, and grouping them into related Holons.
These steps enable efficient visualization of data in Reflect, as well as seamless integration of data from multiple sources into a unified format.
This structured approach enhances the accessibility and usability of data for further analysis and decision-making.
Why does Capish need to curate data?
Curation is needed in order for the solution to access data in a faster, more structured and efficient way and take advantage of the subtleties that reflective logic and modeling entail. The ability to compare data from different sources is only possible if the data is modelled and curated correctly. Ultimately, Capish wants to help the user to be able to explore and control their data.
Capish Pronto
The ready to go applications are ideal for jump starting a project, since they are built on proven workflows and popular features. By reusing successful designs, you can save time, reduce costs, and minimize risks.
What is Capish Pronto?
Capish Pronto is the name of our Ready to Go Applications, a set of standardized features and configurations, purposefully designed as toolboxes for specific roles, tasks, and workflows.
What are the benefits of using an application that is ready to go?
The Capish Pronto applications are built on proven workflows and popular features. By reusing successful designs, you can save time, reduce costs, and minimize risks.
What if our organization has unique needs?
The Capish Pronto applications are highly flexible and do not limit how Capish Reflect can be customized and configured. Starting with pre-defined and ready applications often makes it easier to develop a more tailored solution.
Who are the applications ideal for?
These applications are ideal for organizations looking for a fast and reliable solution to common challenges and workflows, while maintaining the option for customization.
How quickly can a Capish Pronto application be deployed.
Usually, some application features must be optimized to match your unique data. An inventory of your data is required in order to present reliable estimates.

Customers
Capish has chosen to focus on companies and organizations within Life Science and Healthcare, but the solutions and products are applicable in other areas as well.
Who are Capish’s typical customers?
Capish’s customers include pharmaceutical companies, biotech firms, clinical research organizations (CROs), and academic research institutions. These clients use Capish’s solutions to manage, visualize, and draw insights from large datasets in clinical trials and other research activities.
Who can benefit from using Capish Reflect?
Capish Reflect is ideal for professionals in the life sciences, including clinical researchers, data scientists, and regulatory affairs specialists who need to organize, visualize, and analyze clinical and scientific data. It’s particularly beneficial for teams managing complex datasets in clinical trials.
The user groups that could benefit from Capish Reflect, tailored for different roles within an organization are:
Researchers
Researchers can use Capish Reflect to navigate and interpret large sets of research data, facilitating more informed conclusions and accelerating the research process.
Business Executives/Decision-Makers
Executives can rely on Capish Reflect for high-level visualizations and data summaries that inform strategic decisions, providing clear insights into key performance indicators and trends.
Clinical and Trial Design Teams (for Life Sciences)
Clinical and trial design teams can utilize Capish Reflect to analyze historical trial data, identify patterns, and optimize the planning of new clinical studies. By reviewing previous studies, they can make data-driven decisions about study protocols, inclusion/exclusion criteria, patient outcomes, and safety reports, ensuring more efficient trial designs, improved resource allocation, and better overall decision-making and reporting.
Compliance and Regulatory Teams
These teams use Capish Reflect to ensure data integrity, track compliance metrics, and generate reports required for regulatory submissions.
Data Stewards and Data Managers
These users oversee the organization’s data quality and governance, utilizing Capish Reflect’s capabilities to maintain data accuracy, consistency, and reliability.
What are a company's benefits in choosing Capish's solutions and products?
Capish streamlines workflows by reducing the time spent waiting for data and minimizing dependencies, which in turn lowers operational risks.
By accelerating processes from discovery to approvals, it enables faster decision-making and more efficient operations.
In essence, Capish helps companies save time, reduce costs, and mitigate risks and uncertainties, ultimately enhancing productivity and business outcomes.
Why should customers choose Capish Reflect?
Capish’s product empowers users by giving them direct access to a wealth of data, eliminating the need to request new graphs or reports.
With the ability to explore and analyze data based on their own hypotheses, users can search, filter, and create cohorts independently.
Navigating from aggregated to granular data identify similar patients based on key attributes, enabling the creation of meaningful cohorts for comparison. With its ontology-driven structure, comparing data is more intuitive and accurate, allowing for deeper insights and better-informed decisions.
Capish streamlines workflows by reducing the time spent waiting for data and minimizing dependencies, which in turn lowers operational risks. By accelerating processes from discovery to approvals, it enables faster decision-making and more efficient operations.
In essence, Capish helps companies save time, reduce costs, and mitigate risks and uncertainties, ultimately enhancing productivity and business outcomes.

Ontologies
Ontologies ensure that Capish Reflect can effectively interpret and work with variables by clearly defining them. This capability makes Capish an ideal solution for projects requiring cross-domain data integration.
What is an ontology?
An ontology is a structured framework for representing knowledge within a specific domain. It includes a set of terms and concepts that are linked to one another, illustrating their relationships. Ontologies can be used to describe a particular area of knowledge, such as the definition of blood pressure, or they can extend to cover both metadata and data values, facilitating the description of results within a database.
What does Capish's ontology look like?
Capish’s ontology is built around three key concepts: Holon, Field, and Relations. Fields represent the metadata associated with data values and correspond to variables within tables. Each Field is assigned to one or more Holons, which are groupings of variables that collectively describe a specific concept.
These Holons are interconnected through Relations, forming a graph structure. As such, Capish’s ontology serves both as an information model and a terminology system, and it can also be considered a metadata repository.
What is the purpose of Capish’s ontology?
The primary purpose of Capish’s ontology is to ensure that Capish Reflect can effectively interpret and work with variables by clearly defining them, such as distinguishing between categorical and numerical values.
Additionally, it organizes these variables into related Holons, enabling comprehensive insights, such as retrieving all relevant details about a specific patient’s medical history. Capish’s ontology is also crucial for harmonizing data that originates from different standards, providing a general common format that improves consistency and facilitates seamless integration.
This enhances the organization, accessibility, and usability of data for more efficient decision-making.
Are there existing ontologies that effectively integrate data across multiple domains?
While many standardized ontologies exist within specific domains, Capish’s ontology is uniquely designed to bridge these gaps. It allows for seamless integration of data from different domains, providing a flexible and scalable framework that can unify and harmonize diverse datasets.
This capability makes Capish an ideal solution for projects requiring cross-domain data integration, ensuring that information from multiple sources can be effectively combined and utilized.
How does Capish’s ontology adapt to evolving and diverse data structures?
Capish’s ontology is designed to be highly flexible and easily expandable, making it ideal for managing variable and unstructured data that is frequently updated. Its modular structure allows for seamless incorporation of new variables, relationships, and concepts without disrupting existing data models. This adaptability ensures that the ontology evolves alongside the data, enabling users to keep pace with changing requirements and uncover insights from even the most dynamic and complex datasets.
Can Capish adapt to CDISC Terminologies?
Yes, Capish’s ontology can easily adapt to CDISC Terminologies when provided or required by clients. If CDISC Terminologies are not supplied, Capish can work with its own terminology system, offering flexibility in managing clinical trial data.
By mapping to CDISC standards when available, Capish ensures compliance with industry norms, while its own terminology system provides a robust alternative, allowing seamless integration and interpretation of clinical data across various systems.
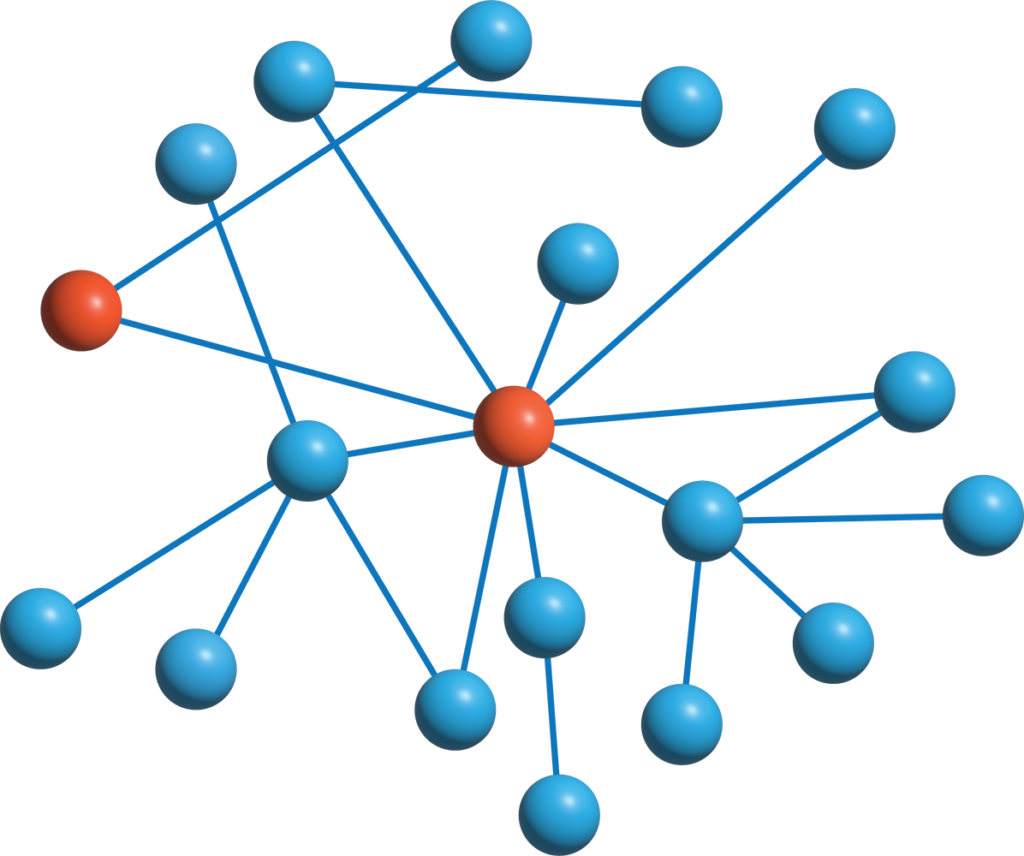
Graph data
Graph database enables faster information retrieval and makes it easy to uncover connections between data. The graph data's unique structure goes beyond what relational databases offer, making it easy to uncover hidden connections and patterns.
What is Graph Database Technology?
Graph databases are optimized for handling relationships between data points, allowing for efficient querying and exploration of interconnected datasets.
This approach is particularly well-suited for life sciences data, where understanding connections between patients, treatments, and outcomes is crucial.
What are the advantages of Capish’s graph database approach?
Capish’s graph database approach enables faster information retrieval and makes it easy to uncover connections between related and seemingly unrelated data, providing deeper insights with efficiency. Its unique structure goes beyond direct relationships, making it easy to uncover hidden connections and patterns.
This capability enhances data exploration and supports deeper, more meaningful insights, empowering users to make well-informed decisions with greater efficiency.
What is an information graph?
Conceptual information graph, used by Capish, organizes data as a network of interconnected concepts, mimicking the way the human brain processes and links information. This innovative approach enables users to intuitively explore relationships within complex datasets, offering a more natural and efficient way to navigate and understand data compared to traditional table-based formats.
Services
Capish regularly updates the platform with new features and improvements. Training can be customized to meet specific needs, and our team is available through multiple channels.
How scalable is the platform?
Our platform is highly scalable, capable of supporting growing data volumes and increasing user demand. Whether you’re a small team or a large organization, our solution adapts to your needs.
Is there ongoing maintenance and updates?
Yes, Capish regularly updates the platform with new features, improvements, and security enhancements. Capish also provides ongoing maintenance to ensure the system runs smoothly and efficiently.
How secure is the data in the system?
Capish’s platform follows industry-leading security protocols to ensure your data is protected. Capish implement robust encryption and access controls to maintain confidentiality and integrity.
How is customer support handled?
Capish provide dedicated customer support to assist with any technical issues or questions. The team is available through multiple channels and offers ongoing assistance to ensure smooth usage of the platform.
What training is provided for new users?
We offer comprehensive training sessions to help users get the most out of our application. Training can be customized to meet the specific needs of your team, ensuring a seamless onboarding experience.

Use cases
Capish supports a wide range of needs – from exploring clinical trial data and detecting safety signals to enabling secure collaboration and regulatory submissions. The platform adapts to evolving workflows, making it easy to reuse data and uncover insights and stay aligned across research and safety efforts.
What makes it worth the time and investment for the customer to replace or add another system?
Capish offers long-term value by curating the data once, allowing you to add or remove data at different stages as needed. The data becomes reusable, ensuring that the initial investment in setup pays off over time. This means that once data is available in the solution, it remains accessible for exploration and can be leveraged across various use cases, maximizing its value and minimizing future effort.
What challenges do pharmaceutical, and healthcare companies face that Capish addresses?
Pharmaceutical and healthcare companies face challenges such as:
- Data Sharing: Difficulty in securely and efficiently sharing data across teams and external partners.
- Data Repository Management: Struggles with organizing and tracking large volumes of data across multiple sources.
- Safety Review and Signal Detection: Challenges in identifying and understanding safety signals from clinical trials and post-market data.
- Regulatory Compliance: Issues in ensuring seamless data submission to regulatory bodies and meeting compliance requirements.
- Research: Facilitating efficient access to and use of research data for better decision-making.
- Commercialization: Streamlining the process of transforming research findings into actionable commercial insights.
Capish provides solutions to these challenges by enabling secure data sharing, improving data management, supporting compliance, and facilitating research and commercialization efforts.
What challenges in ongoing clinical trials can Capish help solve?
Ongoing clinical trials often face the following difficulties:
- Handling Oddities and Metadata: Addressing inconsistencies in trial data and managing complex metadata.
- Managing multiple data sources: Synchronizing data content and timelines.
- Data Visualization: Visualizing data from global projects to uncover patterns and trends early.
- Data Tracking: Managing multiple clinical trials simultaneously and identifying subgroups within the data.
Capish enables clinical trial teams to streamline data handling, improve visual insights, and coordinate complex trial activities more effectively.